Pthreads
1. 概念区分
1.1 线程与进程
| 区别 | 进程 | 线程 |
|---|---|---|
| 定义 | 是正在运行的程序实例,是系统资源分配和调度的基本单位 | 是进程内部的执行单元 |
| 内存 | 拥有独立的地址空间 | 共享地址空间,但拥有独立的栈和寄存器状态 |
| 通信方式 | 发送和接收消息 | 直接读写共享内存 |
| 开销 | 需要操作系统内核调用 | 由线程库管理,开销相对较小 |
| 隔离性 | 进程崩溃不会影响其他进程 | 一个线程崩溃可能导致整个进程及其所有线程崩溃 |
| 资源 | 每个进程有独立的资源 | 共享父进程资源 |
| 适用场景 | 强隔离、高安全性需求的服务或跨机器分布式应用 | 需要高并发、细粒度并行或轻量级任务调度的场景 |
1.2 Pthreads 和 MPI
| 不同之处 | Pthreads | MPI |
|---|---|---|
| 编程模型 | 基于线程,一个进程内部创建多个线程并发执行 | 基于进程,多个独立进程通过消息传递协同工作 |
| 内存模型 | 共享内存,所有线程共享同一进程的地址空间 | 分布式内存,每个进程拥有独立地址空间,数据通过消息传递交换 |
| 通信机制 | 使用共享变量实现线程之间的数据共享 | 使用显式的消息传递函数进行数据交换 |
| 启动方式 | 由主线程显式创建多个线程 | 通过 mpirun/mpiexec 等外部脚本工具启动多个进程 |
2. Pthreads 程序
2.1 框架
程序流程
- 通过命令行参数获取线程数量
- 全局资源初始化,并为 pthread_t 分配内存空间
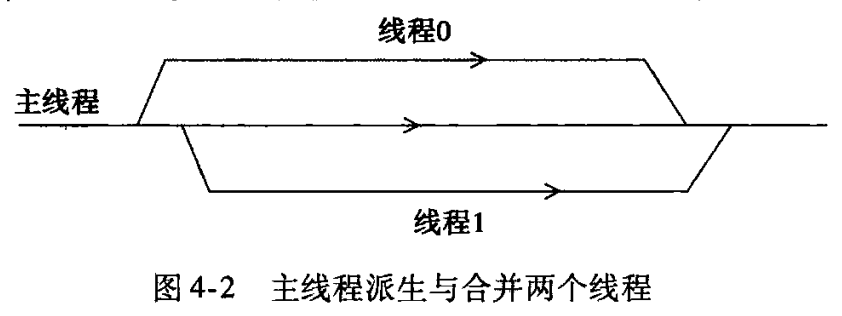
- 主线程创建工作线程,指派工作函数
- 工作线程和主线程同步执行
- 主线程合并工作线程,获取任务结果
- 清理全局资源
执行细节
pthread_t:用于标识线程的数据类型,需要在创建线程前声明,是一个不透明的句柄,传递给内部函数使用void*:表示通用指针类型,可以指向任意类型的数据,工作函数在使用时需要强制转换为具体类型的指针
2.2 派生
1 | int pthread_create( |
- thread:指向 pthread_t 变量的指针,调用成功后它包含新线程的标识
- attr:指向线程属性对象的指针,用于设置线程的属性,通常传 NULL 表示使用默认属性
- worker:指向线程启动函数的指针,新线程会从这个函数开始执行,要求该函数必须接受一个 void* 类型的参数,同时返回一个 void* 类型的结果
- arg:指向传递给线程启动函数的参数的指针,如果不需要传递数据则传递 NULL
- 返回值:成功则返回0,失败则返回非零错误码
2.3 合并
1 | int pthread_join( |
- thread:等待合并的线程
- retval:指向 void * 的指针,*retval 将被设置成线程函数的返回值;若不需要,可传 NULL
- 返回值:成功则返回0,失败则返回非零错误码
2.4 Hello 程序实例
1 |
|
可以简单的把 thread_size 作为全局变量,这样每个线程都可以直接访问
3. 竞争条件
3.1 临界区
竞争条件:当多个线程都要访问共享资源,且至少其中一个访问是更新操作时,其线程调度和执行顺序的不确定性可能导致错误或不可重复的行为
临界区:对共享资源进行更新的代码段,为了避免竞争条件,需要保证一次只有一个线程进入临界区
线程安全的:多个线程并发执行同一代码时,不会导致数据竞态、数据损坏或其他未定义行为
3.2 实例分析
假设有 n 个项和 t 个线程,利用公式 估算圆周率
1 | // 假设 thread_count 和 pi 是全局变量 |
不同线程可能对共享变量 pi = pi + local_sum; 同时进行更新,如果两个线程都读到了 pi = a,先后进行 +b 和 +c,那么先写的值可能会被后写的值覆盖,即原本 pi = a + b + c 变为了 pi = a + c


3.4 忙等待
只有条件满足的线程才可以进入临界区,否则会一直循环检查条件
- 编译优化可能会改变指令的书写顺序,导致忙等待失效
- 处于忙等待的线程实际上一直在运行,会占用 CPU 资源
- 线程不停地在等待和运行之间切换,造成较大开销,导致程序性能下降
1 | // 全局变量 |
这样做会强制按编号大小顺序进行更新
3.5 互斥量
只有拿到互斥量的线程才可以进入临界区,进入临界区前需要请求互斥量并进行加锁,离开临界区后需要对互斥量进行解锁
初始化互斥锁:attr 可设定锁类型,一般传 NULL 表示默认类型
1
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr);
销毁互斥锁:释放其占用的系统资源
1
int pthread_mutex_destroy(pthread_mutex_t *mutex);
加锁:请求互斥量,如果已被加锁则阻塞等待直到获得锁
1
int pthread_mutex_lock(pthread_mutex_t *mutex);
解锁:释放互斥锁,使其他被阻塞的线程可以继续获取
1
int pthread_mutex_unlock(pthread_mutex_t *mutex);
使用流程
1 | // 全局变量 |
3.6 信号量
本质是一个整型计数器,通过对其执行“减一”和“加一”操作
二元信号量:实现互斥,值只有 0 或 1,等效于互斥锁
计数信号量:实现生产者-消费者模型,值可以大于 1,表示可以同时允许多个线程访问资源,或表示某个资源剩余的可用量
需要引入头文件 <semaphore.h>
初始化信号量:pshared=0 表示线程间共享,pshared=1 表示进程间共享;value 是信号量的初始值
1
int sem_init(sem_t *sem, int pshared, unsigned int value);
销毁信号量:释放其内部资源
1
int sem_destroy(sem_t *sem);
等待信号量:如果 sem > 0 则进行减一操作并立即返回,否则阻塞等待被唤醒(不会减一)
1
int sem_wait(sem_t *sem);
释放信号量:对 sem 进行加一操作,如果有线程被阻塞挂起,则唤醒其中一个
1
int sem_post(sem_t *sem);
使用流程
1 |
|
3.7 条件变量
条件变量本身并不保存任何状态,它只是一个等待队列的标识,线程可以挂起在条件变量,然后由另一个线程将挂起的线程逐个唤醒或统一唤醒
初始化条件变量:attr 通常传 NULL
1
int pthread_cond_init(pthread_cond_t *cond, const pthread_condattr_t *attr);
销毁条件变量:释放其内部资源
1
int pthread_cond_destroy(pthread_cond_t *cond);
等待:调用该函数的线程必须要先拥有互斥量,其内部会先解锁从而允许别的线程进入临界区,然后挂起当前线程,最后当前线程被唤醒又加锁,三个操作被封装为一个原子操作
1
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
单点唤醒:唤醒至少一个正在等待的线程
1
int pthread_cond_signal(pthread_cond_t *cv);
广播唤醒:唤醒全部正在等待的线程
1
int pthread_cond_broadcast(pthread_cond_t *cond);
3.8 区别
| 特性 | Mutex(互斥锁) | Semaphore(信号量) |
|---|---|---|
| 用途 | 保护共享资源的独占访问 | 控制资源的可用数量或线程/进程的同步 |
| 持有者 | 必须由 lock 的线程 unlock | 任何线程都可 post |
| 计数 | 只能是 0 和 1 | 任意非负整数 |
| 典型场景 | 保护全局变量、数据结构的互斥访问 | 限流、生产者-消费者模型、实现可重用屏障 |
互斥量和信号量都无法手动操控唤醒哪个线程
4. 路障
4.1 忙等待+互斥量
用一个互斥量实现一个初始值为 0 的全局共享计数器的互斥访问,每个线程进入临界区则递增计数器,然后进入循环等待计数器的值等于线程数量
- 无法重用 counter 实现第 2 个路障:第 1 个路障中无法确定每个线程将 counter 归零是同步执行的,很可能某个线程已经进入第 2 个路障将 counter++ 了,这样会使得 counter 值被反复归 0,导致第 2 个路障忙等待的 counter < thread_count 条件永远为真,无法结束忙等待
- 可能的竞争条件:可能有的线程先跳出条件循环,并且更改了 counter 值,那么晚跳出的线程可能永远无法结束忙等待
1 | void Barrier(...) { |
4.2 信号量
一个初始值为 1 的信号量 counter_sem 用于实现全局共享计数器的互斥访问,一个初始值为 0 的信号量 barrier_sem 用于阻塞线程,对于进入临界区的线程,如果不是最后一个线程,则递增计数器并阻塞,而最后一个会将计数器归零,然后逐一释放阻塞的线程
- 无法重用 barrier_sem 实现第 2 个路障:某些线程可能已经进入第 2 个路障并且
sem_wait(&barrier_sem),但是第 1 个路障中最后一个线程仍然在执行sem_post(&barrier_sem),导致信号量作用域发生混乱 - 最后一个线程要执行 thread_count–1 次 sem_post,性能很差,第一个被唤醒和最后一个被唤醒的线程可能隔了很长时间
1 | void Barrier(...) { |
4.3 互斥量 + 条件变量
一个初始值为 1 的信号量 counter_sem 用于实现全局共享计数器的互斥访问,一个条件变量用于阻塞线程,对于进入临界区的线程,先递增计数器,如果不是最后一个线程,则循环阻塞(防止假唤醒和未知错误),如果是最后一个线程,会将计数器归零,然后一次性唤醒全部挂起线程
1 | void Barrier(...) { |
条件变量的 pthread_cond_wait 从语义上完全可以用信号量和互斥量等价替换,但是这样做就不再是原子操作,而由于间隙的存在,可能会导致当前线程还没有被挂起,第 1 个路障就开始唤醒所有阻塞线程,导致当前线程永远无法被唤醒或者到第 2 个路障才被唤醒,造成不可预知的错误
1 | pthread_mutex_unlock(&mutex); // 给当前线程解锁 |
5. 读写锁
当多个线程同时访问链表且至少有一个线程正在执行 Insert 或 Delete 操作,则会导致程序不安全
插入删除竞争:某个线程向链表 A->B 中插入节点 C,但是在执行插入操作时前节点 A 或后节点 B 被其他线程删除,导致插入到无效位置或链表断裂
查询删除竞争:某个线程读取链表中某个节点的值,但是该节点在读取时被其他线程删除,导致访问内存违规
| 方法 | 流程 | 优势 | 局限性 |
|---|---|---|---|
| 对链表上锁 | 所有对链表的操作都先获得锁才能执行 | 实现简单 | 并发性差,所有线程争用同一把锁 |
| 对节点上锁 | 为链表中的每个节点分配独立的锁变量成员,在操作时仅对涉及的节点加锁 | 细粒度 | 增加存储开销,可能导致更多的锁等待延迟 |
| 对操作上锁 | 针对读和写操作在操作期间对需要保护的区域加锁 | 高并发性 | 设计和实现较复杂 |
读写锁:当一个线程以读锁的方式加锁时,其他线程也可以获取读锁;当一个线程以写锁的方式加锁时,其他线程既不能获得写锁也不能获得读锁
- 在读多写少的情况下,读写锁能够充分发挥并行的优势
- 随着写操作的比重上升,写锁会更频繁地排他占用链表,导致并行性下降
- 无论哪种锁方案,写操作增多时,线程数增加都会导致更明显的争用和排他锁等待,性能增长受限
- 给节点进行加锁和解锁的开销太大,始终是最低效的
因为写操作通常较难获得锁,会导致“写饥饿”问题,因此解锁时系统可能更偏向给予等待写锁的线程优先权

6. 缓存
6.1 缓存一致性
缓存:是处理器介于 CPU 核心和主存之间的小容量高速存储,用来临时保存最近或最常访问的数据,减少频繁访问主存
- 局部性原理:如果一个处理器在时间 t 访问内存位置 a,那么很可能它在一个接近 t 的时间访问接近 a 的内存位置
- 装载策略:一次把与被访问地址同一行(通常 64 B)内的所有字节都读入缓存
缓存一致性:每个核心都有自己私有的缓存副本,可能会把同一内存行加载到各自缓存中,如果某一个核心修改了缓存行,那么就需要把该更新广播到其他缓存,或者写回内存让其他核心重新读取新行
考虑矩阵-向量乘法
- 高矩阵():y 很大,缓存无法容纳所有待写入位置,容易导致写缺失
- 宽矩阵():x 很大,缓存无法容纳所有待读入位置,容易导致读缺失

6.2 伪共享
多个线程在并行访问或更新具体地址不同但是在同一缓存行上的变量时(全局变量),即使两个变量毫无关联,但仍然会引发频繁的缓存一致性问题,两个核会反复抢占同一缓存行,即两个线程一直在互斥访问缓存行,从而严重下降并行性能
- 尽量在线程本地完成操作,最后由主线程做一次集中归约,避免频繁写共享位置
- 数据对齐与填充,强行让一个变量独占一个缓存行
1 | struct { |