OpenMP
1. 概述
OpenMP 是针对共享内存系统进行并行编程的 API,通过在源代码中插入编译指令,编译器会根据程序中添加的 #pragma 指令,自动创建线程将程序并行处理
| 区别 | OpenMP | Pthreads |
|---|---|---|
| 线程创建 | 由编译器自动创建 | 需要手动创建 |
| 使用方式 | 加入 #pragma 编译指令标记并行区域 | 调用 pthread_h 库中的函数 |
| 控制粒度 | 粗粒度,由运行时系统自动处理 | 细粒度,可以人为干预部分过程 |
2. 程序
2.1 omp 库函数
获取当前并行区域中的线程编号(从 0 开始)
1
int omp_get_thread_num(void)
获取当前时间戳
1
double omp_get_wtime(void)
判断当前是否处于并行区域
1
int omp_in_parallel(void)
获取系统可用的处理器数量
1
int omp_get_num_procs(void)
获取系统最大可创建的线程数量
1
int omp_get_thread_limit(void)
设置 / 获取在并行区域中的线程数量
1
2void omp_set_num_threads(int n)
void omp_get_num_threads(void)设置 / 获取动态调整线程功能
1
2void omp_set_dynamic(int flag)
int omp_get_dynamic(void)设置 / 获取嵌套并行功能
1
2void omp_set_nested(int flag)
int omp_get_nested(void)设置 / 获取线程调度策略
1
2void omp_set_schedule(omp_sched_t, int)
void omp_get_schedule(omp_sched_t *kind, int *chunk)
2.2 编译指令
以 #pragme omp 开头的编译器指示,后面使用花括号括起并行区域的代码块(花括号放在新的一行)
设置一个并行区域,让编译器自动创建线程,并将代码块并行化
1
设置路障,所有线程到达此处才能继续
1
对紧随其后的简单操作原子化处理,保证该语句在并行执行时不会被打断
1
设置一个临界区,确保同一时刻只有一个线程能够执行并行区域
1
设置并行区域内仅由一个线程执行,其他线程在此隐式阻塞
1
设置并行区域内仅有主线程执行,其他线程不阻塞也不执行
1
创建并行迭代区域,只负责迭代
1
在并行区域中,分配线程执行迭代
1
2.3 子句
添加在编译指令 #pragma omp parallell 后,用来控制并行区域的行为
声明并行区域的线程数量
1
声明每个线程的私有变量,初始值是未定义的
1
声明每个线程的私有变量,初始值与进入并行区前一致
1
声明每个线程的共享变量
1
声明每个线程的变量的默认属性(none 要求必须显式声明每个变量是 shared 还是 private)
1
根据指定条件决定是否并行
1
对指定变量做归约操作,常用的有 +、*、max、min,会自动规避竞争条件
1
去掉迭代最后的隐式屏障
1
指定迭代的调度方式
1
3. 迭代并行
3.1 方式
迭代并行:用 for 构造把循环拆成多份,让各线程同时跑不同的迭代,但是对 for 循环具有以下要求
- 不能无限循环
- 不能含有跳出语句,如 break 或 return
- 循环变量必须是整数类型或指针类型
- 循环变量只能被 for 语句中的增量表达式修改
- 循环表达式不能被更改
- 循环迭代间应该相互独立,不存在数据/循环依赖
实现方式
#pragma omp for:在一个已经存在的并行区域内部使用,将紧跟其后的 for 循环的迭代自动分配给各线程执行,只负责分工给已有线程,不负责创建线程1
2
3
4
5
6
7
8
9
10
{
// … 并行初始化/私有变量定义 等 …
for (int i = 0; i < N; i++) {
A[i] = f(i);
}
// 隐式屏障:所有线程等到循环所有迭代都做完后再继续
}#pragma omp parallel for:既创建并行区域、创建线程,又并行分配循环,在后面不需要花括号,直接紧跟 for 循环1
2
3
4
5
for (int i = 0; i < N; i++) {
A[i] = f(i);
}
// 隐式屏障:所有线程等到循环所有迭代都做完后再继续
对比分析
| 特性 | pragma omp for | pragma omp parallel for |
|---|---|---|
| 颗粒度 | 并行区域包裹的范围可自行控制,可在一个并行区域内写多个 for | 并行区域只包含紧跟的那个循环;循环结束即并行区结束,后续代码串行执行 |
| 线程开销 | 并行区只创建/销毁一次线程,开销较低 | 每个 parallel for 都会创建/销毁一次线程,开销较高 |
| 适用场景 | 当有多段并行计算需要复用同一批线程或要并行多次循环时首选 | 只需并行单次循环、代码简洁时首选 |
不能混用两种模式
3.2 奇偶换位排序
pragma omp parallel for:内循环负责创建线程团队
1 | for (phase = 0; phase < n; phase++) { |
pragma omp for:外循环负责创建线程团队
1 |
|
3.3 调度策略
通过子句 schedule(<type>, [chunksize]) 指定调度类型 type 和块大小 chunksize
| 方式 | 描述 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| default | 按照 n / thread_count 的块大小分配给线程,本质就是 static | 同下 | 同下 | 同下 |
| static | 将所有迭代按照固定的块大小和顺序分配给各个线程 | 调度开销最低 | 负载不均时会导致慢线程拖尾 | 每次迭代耗时均匀,循环体开销可预测 |
| dynamic | 动态分配迭代块,线程完成一个块后从剩余迭代中动态获取新的块 | 自动负载均衡 | 调度开销高,频繁抢块会增加同步延迟 | 各迭代执行时间差异大,需要细粒度负载平衡 |
| guided | 每次分配的块大小会从“剩余迭代数/线程数”递减到指定的最小块大小 | 折中 static 与 dynamic:前期大块减调度,后期小块平衡 | 实现复杂 | 前期迭代重、后期迭代轻 |
| auto | 让编译器自动选择最合适的调度策略 | 无需手动调参 | 策略不可见,不易预测性能 | 对性能可控性要求不高,或希望交由编译器自动优化 |
| runtime | 调度方式由运行时环境变量 OMP_SCHEDULE 指定 | 运行时可调,无需重编译 | 需要额外配置环境变量 | 需要在部署时动态调优或方便快速试验不同策略 |
假设有 12 个迭代和 3 个线程
schedule(default) / schedule(static, 4)
- Thread0:0,1,2,3
- Thread1:4,5,6,7
- Thread2:8,9,10,11
schedule(static, 2)
- Thread0:0,1,6,7
- Thread1:2,3,8,9
- Thread2:4,5,10,11
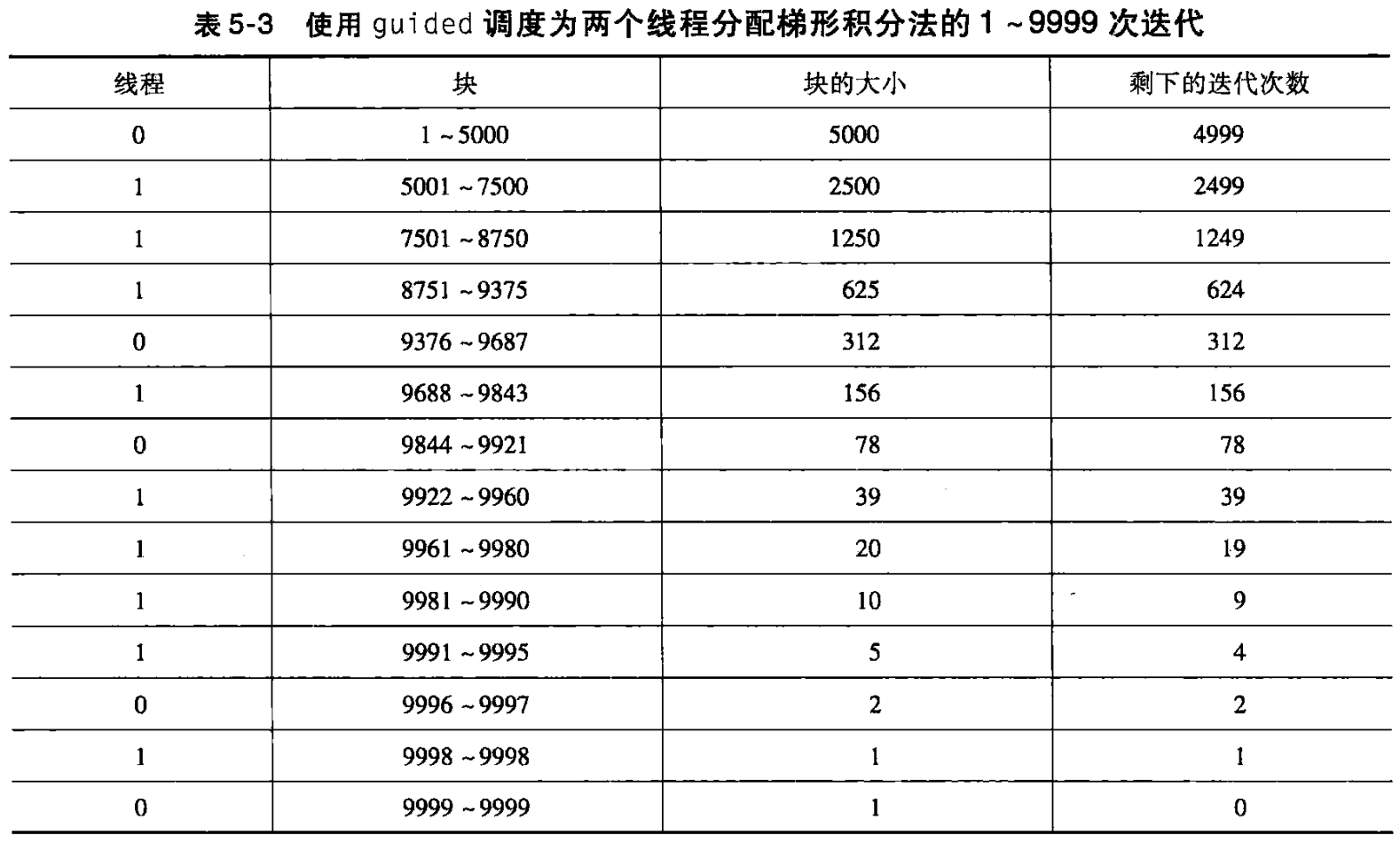
4. 互斥机制
4.1 atomic
只能保护一条 C 语言原子赋值操作所形成的临界区,例如 x <op>= <expression>,x++,++x,x--,--x
expression不能引用 x- 只有 x 的装载和存储可以确保是受保护的,例如
x += y++中的 y 的更新不受保护 - 在后面不需要用花括号
1 |
|
4.2 critical
用于标记代码块临界区,同一时间只能有一个线程能够执行该区域内的代码块,从而保证对共享数据的互斥访问
- 无名:任意两个无名临界区之间都会互斥,即使它们是不同的并行区域,这会导致原本两个独立不互斥的操作被迫互斥
- 命名:不同名称的临界区使用不同的锁,有名称和无名称的临界区也使用不同的锁,都不会相互排斥
1 |
|
4.3 omp_lock_t
通过 omp_lock_t 类型的锁和相关函数进行互斥控制,适用于互斥的是某个共享资源而不是一整个代码块
初始化锁
1
void omp_init_lock(omp_lock_t *lock)
销毁锁
1
void omp_destroy_lock(omp_lock_t *lock)
加锁:如果锁被占用则挂起阻塞
1
void omp_set_lock(omp_lock_t *lock)
解锁
1
void omp_unset_lock(omp_lock_t *lock)
5. 消息队列
1 |
|