并行概念
1. 并行概念
并行程序设计:将大任务分解为多个可同时执行的子任务,从而利用多核处理器或多台计算机实现更高效的计算
- 提高性能:缩短程序运行时间
- 解决大规模数据问题:处理计算密集型任务
并行计算类型
- 并发计算(cocurrent):一个程序的多个任务可以在同一个时段内同时执行
- 并行计算(parallel):一个程序的多个任务可以在同一个时刻下同时运行
- 分布式计算(distributed):多个程序通过交互通信可以在同一个时刻下同时运行
并行程序:在并行系统上进行并行计算的程序
- 任务级并行:不同操作对同一数据同时执行,任务之间没有依赖关系,比如对一组数据计算极值和均值
- 数据级并行:同一操作对不同数据同时执行,任务之间具有因果关系,比如对一组数据计算平方
并行系统:在单个芯片上放置多个处理单元所形成的集成电路
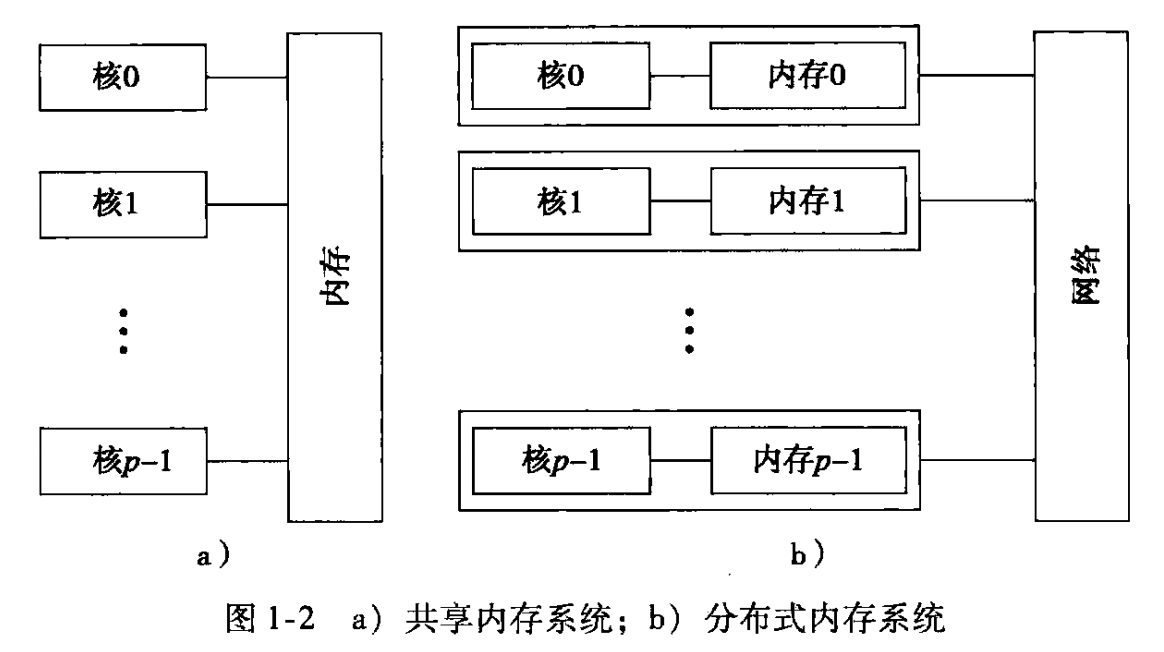
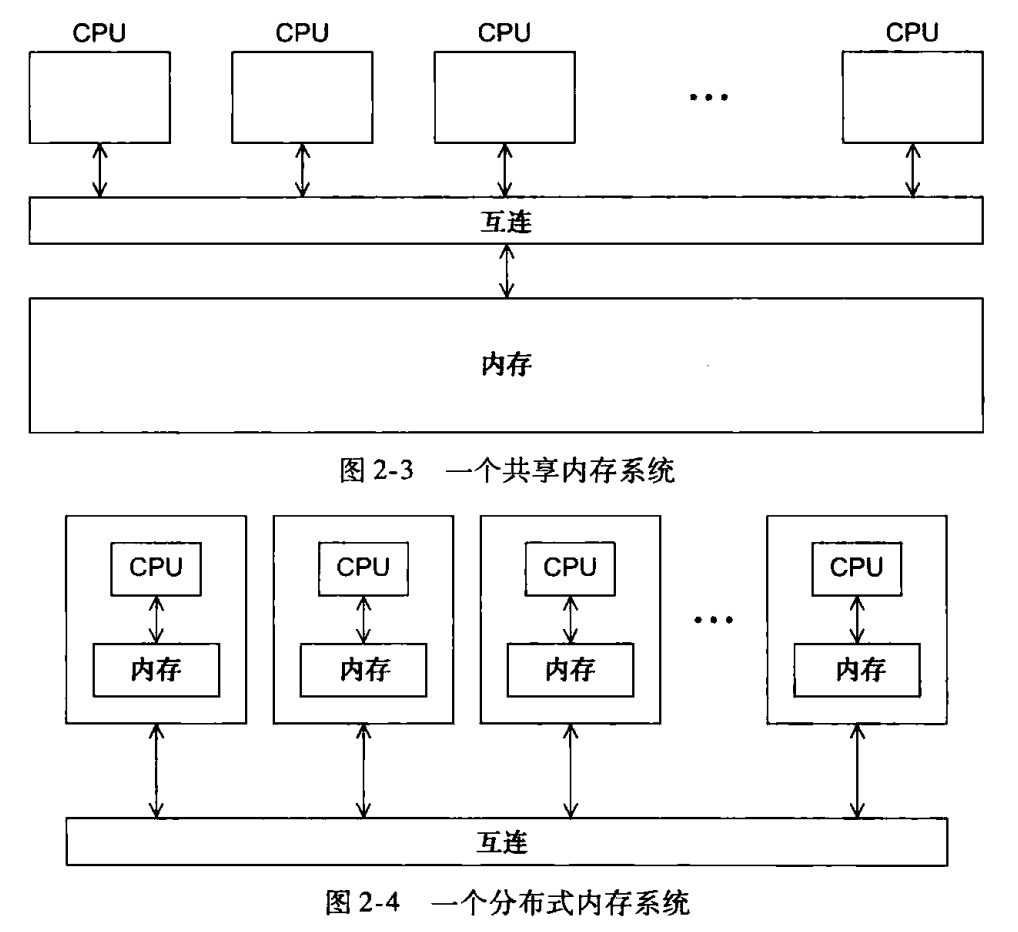
- 共享内存:所有处理单元共享同一物理内存,通过直接访问共享内存实现进程/线程间的通信
- 分布式内存:每个处理单元拥有独立的内存空间,通过显式的发送和接收消息实现进程/线程间的通信
并行方法
| 类型 | 名称 | 并行系统 | 优点 | 缺点 |
|---|---|---|---|---|
| MPI | 消息传递接口 | 分布式内存系统 | 每个处理单元都有独立内存,适合超大规模并行计算 | 显式执行通信语句,编程相对复杂 通信会造成延迟 通信错误可能会导致数据丢失 |
| Pthreads | POSIX 线程 | 共享内存系统 | 能够细粒度控制并行执行 | 共享内存需要处理线程间的同步和互斥问题 |
| OpenMP | 开放多处理 | 共享内存系统 | 适合逐步并行化现有的串行代码 | 指令式并行,难以调试 |
2. 并行硬件
2.1 冯诺依曼体系
CPU 通过读取主存中的指令和数据来执行任务,计算机按照取指-译码-执行-存储这一顺序循环执行
指令级并行(Instruction-Level Parallelism, ILP):在同一时间内执行多条指令,细粒度
流水线:将指令的执行过程划分为多个连续的阶段,每个阶段由专门的硬件单元处理
多发射:在一个时钟周期内发射多条不冲突的指令到不同的执行单元
线程级并行(Thread-Level Parallelism, TLP):在同一时间内执行多个线程,粗粒度
硬件多线程:处理器支持在硬件层面管理和切换多个线程,使得当一个线程阻塞时,其他线程可以继续执行
同步多线程:允许多个线程同时共享和利用处理器的各个执行单元

2.2 并行系统
| 方式 | SIMD | SIMT | MIMD |
|---|---|---|---|
| 定义 | 一个控制单元广播同一条指令给多个算术单元,各算术单元在不同的数据上执行 | 单个控制单元广播同一条指令给多个线程,各线程在不同的上下文上执行 | 每个处理单元都有自己的控制单元和算术单元,可以独立执行不同的指令流和数据流 |
| 特点 | 指令同步,数据并行 | 指令同步,线程并行 | 独立运行,异步运行 |
| 适用 | 向量处理器,信号处理器 | GPU、TPU、CUDA | 多核 CPU,分布式集群 |
2.3 互连网络
共享内存互连网络
- 总线:一种公共通信介质,所有处理单元和内存共享同一传输线路,存在带宽竞争和访问冲突的问题
- 交叉开关:以矩阵方式直连每个发送端到每个接收端,每对端点间都有独立的物理通路

分布式内存互连网络
- 直接互连:节点之间直接按照一定的拓扑结构互联,每个节点只与相邻或部分范围内的节点直接相连
- 间接互连:通过专用交换设备将各节点连接起来,通信时数据需要经过一个或多个中间节点
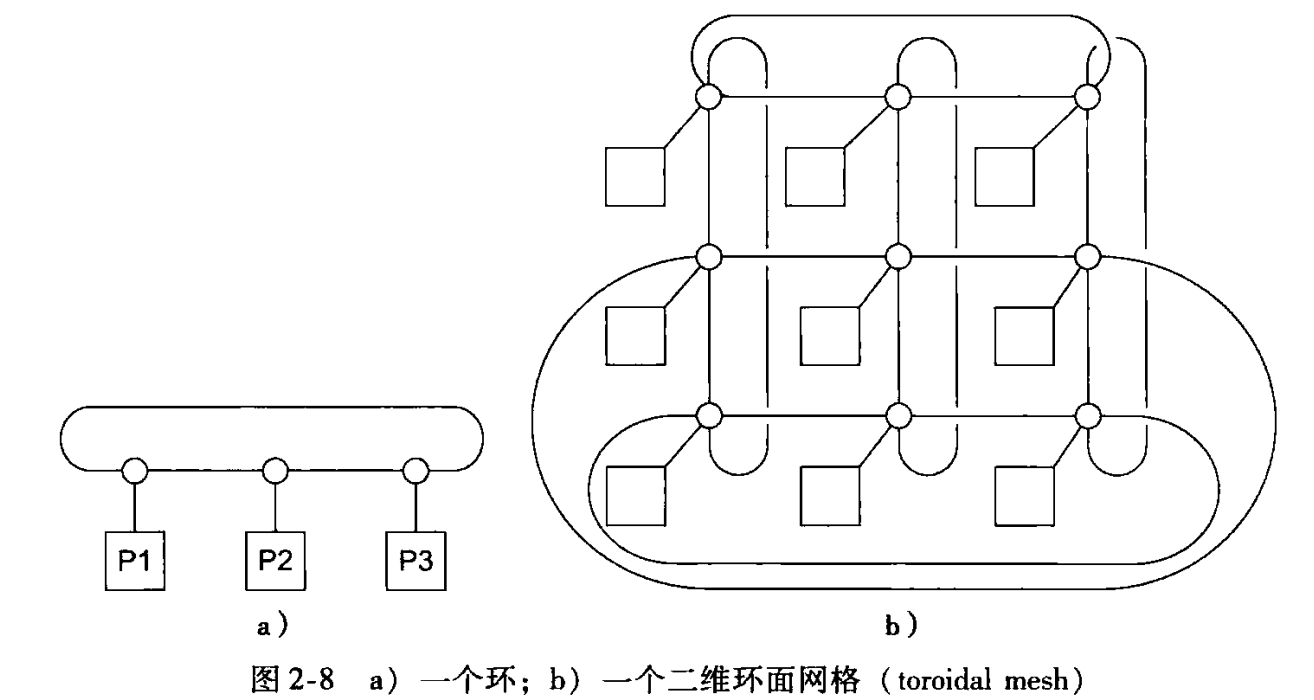
2.4 访问模式
| 属性 | UMA | NUMA |
|---|---|---|
| 定义 | 所有处理器访问任何内存地址的延迟和带宽相同 | 不同处理器访问内存的延迟或带宽不同,本地内存快,远程内存慢 |
| 特点 | 简单的缓存一致性协议,总线带宽易成瓶颈 | 本地访问延迟低、带宽高 跨节点访问需互连网络,延迟高、带宽低 需复杂的内存分配策略 |
| 适用场景 | 对称多处理器系统 | 多插槽服务器、分布式共享内存系统 |
2.5 并行架构
| 类型 | 名称 | 节点 | 连接 |
|---|---|---|---|
| MPP | 大规模并行处理器系统 | 高度集成,统一由全局作业管理器调度 | 使用专用高速互联网络,延迟低、带宽高 |
| COW | 工作站机群系统 | 完全独立,各自运行自己的操作系统,通过消息传递通信 | 使用标准网络,延迟高、带宽低 |
3. 并行软件
3.1 SPMD
单程序多数据(Single Program Mutiple Data):所有进程或线程运行同一份程序代码,但在不同的数据上工作
要求
负载均衡:各个进程或线程的任务量是大致相等的
通信量最小:通信延迟尽可能地低
同步:各个进程或线程发送和接收的通信数据是一致的
互斥:各个进程或线程访问临界区时不会导致竞争
方式
动态线程:主线程根据实际需求在运行时动态创建工作线程
静态线程:主线程编译时派生出固定数量的工作线程(线程池),在运行时复用这些线程
3.2 I/O 处理
- 只允许主进程/线程可以访问 stdin,然后将读取的数据分发到工作线程
- 只允许主进程/线程可以访问 stdout 输出汇总信息,防止输出错乱和拥堵
- 允许所有进程/线程访问 stdout 输出调试信息,但是需要注明进程/线程标识符
- 所有进程/线程都可以访问 stdout 和 stderr,确保错误信息正确输出从而定位改错
3.3 Foster 方法
- 划分:确定问题之间的依赖关系,将问题划分为可以独立解决的子任务
- 通信:确定子任务之间哪些数据需要进行通信交换
- 聚合:将较小的子任务与通信结合成一个聚合子任务
- 分配/映射:将上一步聚合好的任务分配到处理器上
4. 并行性能
4.1 加速比
串行执行时间与 p 个处理单元并行执行时间的比值,
不可能获得线性加速比,即 S 不可能等于 p
4.2 效率
- 并行系统中每个处理单元在加速比中所发挥的贡献,
- 效率较低的原因:额外通信开销、负载不均、内存竞争大
4.3 可扩展性
可扩展性:需求增加时通过扩展资源来提升性能的能力
- 强扩展性:保持问题规模不变,增加处理单元数量,执行时间对应减少,表现多核的提速能力
- 弱扩展性:问题规模随着处理单元按比例增大,执行时间保持不变,表现多核的适应能力
4.4 阿姆达尔定律
- 不论有多少核,并行度有多高,串行部分都会成为性能提升的瓶颈,所产生的加速比具有上限
- 假设有 无法实现并行化,则加速比,当,加速比的极限是
4.5 计算 vs 开销
,(忽略并行化中部分串行的执行时间)
| 现象 | 解释 | 本质 |
|---|---|---|
| 进程数不变,规模越大,加速比和效率越大 | 问题规模增大 N 倍时,串行计算时间 增大 N 倍,但并行部分 只增大 N/p 倍,而开销几乎不变 | 并行分摊计算 |
| 规模数不变,进程越多,加速比越大 | 进程数增大 n 倍时,串行计算时间 不变,但并行部分 降低 n 倍 | 多核加快计算 |
| 规模数不变,进程越多,效率越低 | 进程数增大 n 倍时,开销 增大 n 倍 | 多核增加开销 |
需要权衡好多核的【加速收益】和【开销成本】